Stalo se vám někdy, že jste v textovém souboru přidávali či upravovali nějaký text, a najednou se všechno zhroutilo? Kód nefungoval, program vyhazoval chyby, ale vy jste neviděli žádnou chybu. Všechno vypadalo v pořádku. A pak jste zjistili, že tam někde skrývají neviditelná rovnátka.
Tato malá, ale ničivá chyba se objevuje nejčastěji v souborech, které přenášíte mezi různými systémy - třeba když kopírujete text z Wordu do editoru kódu, nebo když přidáváte nastavení do konfiguračního souboru. Neviditelná rovnátka nejsou skutečně rovnátka. Jsou to znaky Unicode, které vypadají jako běžné rovnítka, ale v počítači jsou úplně jiné. A když je program očekává běžný ASCII znak, tak to celé spadne.
Co jsou neviditelná rovnátka?
Neviditelná rovnátka jsou znaky, které se vyskytují v různých Unicode verzích. Nejčastější z nich je znak U+2260 - „nerovná se“, který vypadá jako rovnítko se škrtnutou čárou. Ale nejvíc problémů dělají znaky jako U+FE63 (malé rovnítko) nebo U+FF1D (plné šířky rovnítko). Tyto znaky se používají v jazycích jako čínština, japonština nebo arabština, kde se písmena píší jinak. Když někdo zkopíruje text z webové stránky nebo PDF, kde byl použit takový znak, a vloží ho do souboru, který očekává jen ASCII, tak to vypadá jako normální rovnítko - ale počítač ho nezná.
Ve Windows se tyto znaky často objevují, když kopírujete text z aplikací jako Word, Excel nebo PowerPoint. Tyto programy automaticky nahrazují běžná rovnítka za „krásnější“ verze, které vypadají lépe - ale v kódu to znamená havárii.
Kde se neviditelná rovnátka nejčastěji objevují?
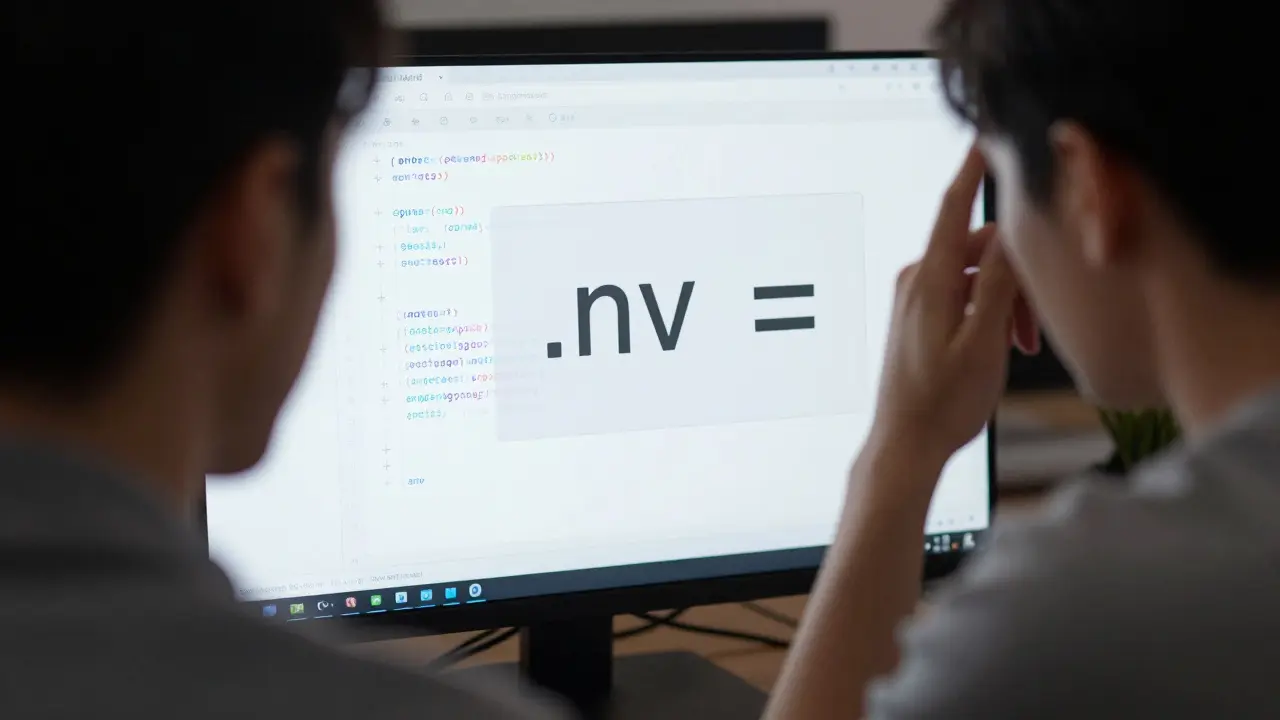
- V konfiguračních souborech (např.
.env,config.json,settings.py) - V souborech s kódem, kde se používají podmínky (např.
if x = y) - V CSV nebo TSV souborech, kde se oddělují hodnoty rovnítky
- V příkazových řádcích, když se přenáší nastavení z jiného systému
- V souborech, které jste získali z webových stránek, e-mailů nebo PDF
Například: Pokud jste v Wordu napsali port = 8080 a pak to zkopírovali do souboru .env pro Node.js aplikaci, může se stát, že tam místo běžného rovnítka je znak U+FF1D. Node.js to nezvládne, a místo toho, aby spustil server, vám vyhodí chybu invalid syntax. A vy si říkáte: „Ale vypadá to správně!“
Jak to detekovat?
Nejednodušší způsob, jak najít neviditelná rovnátka, je použít editor, který je zobrazuje. Většina běžných editorů - jako Notepad++ nebo VS Code - to umí.
V VS Code otevřete soubor, klikněte na tlačítko View → Toggle Render Whitespace. Tam uvidíte všechny mezery, tabulátory a neviditelné znaky. Neviditelná rovnátka se zobrazí jako malé, šedé křížky nebo čtverečky. Pokud vidíte něco, co vypadá jako rovnítko, ale je šedé a jinak tvarované, je to ono.
V Notepad++ jděte na View → Show Symbol → Show All Characters. Tam se všechny skryté znaky ukáží. Neviditelná rovnátka se zobrazí jako — nebo jiné neobvyklé symboly.
Nebo použijte jednoduchý trik: otevřete soubor v Hex Editoru (např. HxD pro Windows). Běžné rovnítko v ASCII má kód 3D. Neviditelná rovnátka mají kódy jako EF BB BF, FF 1D nebo 22 60. Když uvidíte něco jiného než 3D tam, kde by mělo být rovnítko, máte problém.

Jak to opravit?
Nejrychlejší způsob je najít a nahradit všechny nežádoucí znaky. V VS Code nebo Notepad++ použijte funkci Find and Replace. Ale nekopírujte rovnítko z vašeho souboru - to byste mohli zkopírovat i špatný znak.
Místo toho:
- Otevřete prázdný soubor.
- Napište běžné rovnítko (
=) z klávesnice. - Kopírujte ho.
- Vyhledejte všechny znaky, které vypadají jako rovnítko, a nahraďte je tímto správným.
Pokud máte hodně souborů, můžete použít příkazový řádek. Například v Linuxu nebo macOS:
sed -i 's/\xEF\xBB\xBF/=/g' *.envTento příkaz najde znak U+FEFF (BOM - Byte Order Mark) a nahradí ho rovnítkem. Pro jiné znaky změňte kód podle toho, co jste našli v Hex Editoru.
Jak tomu předcházet?
Nejlepší řešení je předcházet problému, než ho řešit.
- Nikdy nekopírujte text z Wordu nebo PDF do kódu. Pokud potřebujete něco přenést, nejprve ho vložte do čistého textového editoru (např. Notepad), a pak z něj zkopírujte do kódu.
- Používejte jen ASCII znaky v konfiguračních souborech. Všechna rovnítka, čárky, tečky a mezery by měla být z klávesnice, ne z webové stránky.
- Nastavte svůj editor na „Show Invisible Characters“. To vám pomůže všimnout si problémů hned, když je vkládáte.
- Používejte linter nebo formátovací nástroje. Nástroje jako
prettier,blackneboeslintmůžou automaticky detekovat a opravit nežádoucí znaky. - Používejte editor s podporou Unicode. VS Code, Sublime Text nebo Atom jsou lepší než starší editory jako Notepad.

Co se stane, když to ignorujete?
Neviditelná rovnátka nejsou jen záležitostí „to nefunguje“. Mohou způsobit:
- Chyby v kódu, které se neobjeví při testování, ale až v produkčním prostředí
- Chybné výsledky v databázích, když se porovnávají hodnoty
- Ztrátu času - někdo stráví hodiny hledáním chyby, která je vlastně jen špatný znak
- Zranění důvěry - pokud se vaše aplikace chová náhodně, lidé si říkají: „Tohle je špatně napsané.“
V jednom případě v Plzni se firma, která vyvíjela software pro městské úřady, nevysvětlila, proč se jejich systém pro výpočet daní chová náhodně. Po týdnu hledání se zjistilo, že někdo zkopíroval vzorec z PDF a vložil ho do Python skriptu. Tam bylo rovnítko, které nebylo rovnítko. A celý systém počítal špatně.
Když už to máte, co dál?
Nejprve najděte všechny soubory, které mohly být ovlivněny. Použijte příkaz:
grep -r "[=]" . --include="*.env" --include="*.py" --include="*.json"Tento příkaz najde všechny soubory, které mají rovnítko. Ale to neřeší neviditelná rovnátka. Pro to potřebujete nástroj jako xxd nebo hexdump.
Po opravě všech souborů je dobré přidat do svého workflow automatickou kontrolu. Například v Gitu můžete použít pre-commit hook, který zkontroluje, zda nejsou v souborech nežádoucí znaky. Tady je jednoduchý skript pro bash:
#!/bin/bash
if git diff --cached --name-only | grep -E "\.(env|py|json|txt)$"; then
for file in $(git diff --cached --name-only | grep -E "\.(env|py|json|txt)$"); do
if grep -q "[\xEF\xBB\xBF\xFF\x1D\x22\x60]" "$file"; then
echo "ERROR: Neviditelné znaky nalezeny v $file"
exit 1
fi
done
fiTento skript zastaví commit, pokud najde nežádoucí znaky. Takže se chyba neztratí do historie.
Závěr
Neviditelná rovnátka nejsou příklad „to se stane jen někomu jinému“. Jsou to běžná, ale nečekaná chyba, která může způsobit značné problémy. A protože vypadají jako normální znaky, tak je těžké je najít. Ale s pravými nástroji a návyky je možné je úplně eliminovat.
Nezapomeňte: když pracujete s textem, který má být strojově čitelný - jako kód, konfigurace nebo data - používejte jen to nejjednodušší. Nejkrásnější znak není ten, který vypadá nejlépe. Je to ten, který počítač pozná.
Co je příčinou neviditelných rovnátek?
Příčinou jsou znaky Unicode, které vypadají jako rovnítka, ale mají jiný kód než běžné ASCII rovnítko (3D). Tyto znaky se často objevují, když kopírujete text z Wordu, PDF nebo webových stránek, kde se používají „krásnější“ verze znaků.
Jak mohu zjistit, zda mám neviditelná rovnátka v souboru?
Použijte editor, který zobrazuje neviditelné znaky - například VS Code s povoleným „Render Whitespace“ nebo Notepad++ s „Show All Characters“. Můžete také otevřít soubor v Hex Editoru a hledat kódy jako EF BB BF, FF 1D nebo 22 60 místo 3D.
Můžou neviditelná rovnátka způsobit bezpečnostní problém?
Nejsou přímo bezpečnostní hrozbou, ale mohou způsobit chyby, které vedou k nečekanému chování systému - například špatnému výpočtu daní, chybnému přístupu k databázi nebo selhání autentizace. To může být využito útočníkem, který využije nečekané chyby k útoku.
Proč se to děje při kopírování z Wordu?
Word automaticky nahrazuje běžná rovnítka za „typograficky lepší“ verze, které jsou součástí Unicode. Tyto znaky nejsou kompatibilní s většinou programovacích jazyků a konfiguračních souborů, které očekávají pouze ASCII znaky.
Jak předcházet těmto problémům v budoucnu?
Nikdy nekopírujte text přímo z Wordu nebo PDF do kódu. Vždy nejprve vložte text do čistého textového editoru (jako Notepad), poté ho zkopírujte do kódu. Používejte editory s funkcí „Show Invisible Characters“ a nastavte automatické kontroly v Gitu nebo v linteru.